

简介
在本实验中,你将为你的操作系统写内存管理方面的代码。内存管理由两部分组成。
第一部分是内核的物理内存分配器,内核通过它来分配内存,以及在不需要时释放所分配的内存。分配器以 页 为单位分配内存,每个页的大小为 4096 字节。你的任务是去维护那个数据结构,它负责记录物理页的分配和释放,以及每个分配的页有多少进程共享它。本实验中你将要写出分配和释放内存页的全套代码。
第二个部分是虚拟内存的管理,它负责由内核和用户软件使用的虚拟内存地址到物理内存地址之间的映射。当使用内存时,x86 架构的硬件是由内存管理单元(MMU)负责执行映射操作来查阅一组页表。接下来你将要修改 JOS,以根据我们提供的特定指令去设置 MMU 的页表。
预备知识
在本实验及后面的实验中,你将逐步构建你的内核。我们将会为你提供一些附加的资源。使用 Git 去获取这些资源、提交自实验 1 以来的改变(如有需要的话)、获取课程仓库的最新版本、以及在我们的实验 2 (origin/lab2)的基础上创建一个称为 lab2 的本地分支:
athena% cd ~/6.828/lab
athena% add git
athena% git pull
Already up-to-date.
athena% git checkout -b lab2 origin/lab2
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
Switched to a new branch "lab2"
athena%
上面的 git checkout -b 命令其实做了两件事情:首先它创建了一个本地分支 lab2,它跟踪给我们提供课程内容的远程分支 origin/lab2 ,第二件事情是,它改变你的 lab 目录的内容以反映 lab2 分支上存储的文件的变化。Git 允许你在已存在的两个分支之间使用 git checkout *branch-name* 命令去切换,但是在你切换到另一个分支之前,你应该去提交那个分支上你做的任何有意义的变更。
现在,你需要将你在 lab1 分支中的改变合并到 lab2 分支中,命令如下:
athena% git merge lab1
Merge made by recursive.
kern/kdebug.c | 11 +++++++++--
kern/monitor.c | 19 +++++++++++++++++++
lib/printfmt.c | 7 +++----
3 files changed, 31 insertions(+), 6 deletions(-)
athena%
在一些案例中,Git 或许并不知道如何将你的更改与新的实验任务合并(例如,你在第二个实验任务中变更了一些代码的修改)。在那种情况下,你使用 git 命令去合并,它会告诉你哪个文件发生了冲突,你必须首先去解决冲突(通过编辑冲突的文件),然后使用 git commit -a 去重新提交文件。
实验 2 包含如下的新源代码,后面你将逐个了解它们:
inc/memlayout.hkern/pmap.ckern/pmap.hkern/kclock.hkern/kclock.c
memlayout.h 描述虚拟地址空间的布局,这个虚拟地址空间是通过修改 pmap.c、memlayout.h 和 pmap.h 所定义的 PageInfo 数据结构来实现的,这个数据结构用于跟踪物理内存页面是否被释放。kclock.c 和 kclock.h 维护 PC 上基于电池的时钟和 CMOS RAM 硬件,在此,BIOS 中记录了 PC 上安装的物理内存数量,以及其它的一些信息。在 pmap.c 中的代码需要去读取这个设备硬件,以算出在这个设备上安装了多少物理内存,但这部分代码已经为你完成了:你不需要知道 CMOS 硬件工作原理的细节。
特别需要注意的是 memlayout.h 和 pmap.h,因为本实验需要你去使用和理解的大部分内容都包含在这两个文件中。你或许还需要去看看 inc/mmu.h 这个文件,因为它也包含了本实验中用到的许多定义。
开始本实验之前,记得去添加 exokernel 以获取 QEMU 的 6.828 版本。
实验过程
在你准备进行实验和写代码之前,先添加你的 answers-lab2.txt 文件到 Git 仓库,提交你的改变然后去运行 make handin。
athena% git add answers-lab2.txt
athena% git commit -am "my answer to lab2"
[lab2 a823de9] my answer to lab2 4 files changed, 87 insertions(+), 10 deletions(-)
athena% make handin
正如前面所说的,我们将使用一个评级程序来分级你的解决方案,你可以在 lab 目录下运行 make grade,使用评级程序来测试你的内核。为了完成你的实验,你可以改变任何你需要的内核源代码和头文件。但毫无疑问的是,你不能以任何形式去改变或破坏评级代码。
第 1 部分:物理页面管理
操作系统必须跟踪物理内存页是否使用的状态。JOS 以“页”为最小粒度来管理 PC 的物理内存,以便于它使用 MMU 去映射和保护每个已分配的内存片段。
现在,你将要写内存的物理页分配器的代码。它将使用 struct PageInfo 对象的链表来保持对物理页的状态跟踪,每个对象都对应到一个物理内存页。在你能够编写剩下的虚拟内存实现代码之前,你需要先编写物理内存页面分配器,因为你的页表管理代码将需要去分配物理内存来存储页表。
练习 1
在文件
kern/pmap.c中,你需要去实现以下函数的代码(或许要按给定的顺序来实现)。
boot_alloc()mem_init()(只要能够调用check_page_free_list()即可)page_init()page_alloc()page_free()
check_page_free_list()和check_page_alloc()可以测试你的物理内存页分配器。你将需要引导 JOS 然后去看一下check_page_alloc()是否报告成功即可。如果没有报告成功,修复你的代码直到成功为止。你可以添加你自己的assert()以帮助你去验证是否符合你的预期。
本实验以及所有的 6.828 实验中,将要求你做一些检测工作,以便于你搞清楚它们是否按你的预期来工作。这个任务不需要详细描述你添加到 JOS 中的代码的细节。查找 JOS 源代码中你需要去修改的那部分的注释;这些注释中经常包含有技术规范和提示信息。你也可能需要去查阅 JOS 和 Intel 的技术手册、以及你的 6.004 或 6.033 课程笔记的相关部分。
第 2 部分:虚拟内存
在你开始动手之前,需要先熟悉 x86 内存管理架构的保护模式:即分段和页面转换。
练习 2
如果你对 x86 的保护模式还不熟悉,可以查看 Intel 80386 参考手册的第 5 章和第 6 章。阅读这些章节(5.2 和 6.4)中关于页面转换和基于页面的保护。我们建议你也去了解关于段的章节;在虚拟内存和保护模式中,JOS 使用了分页、段转换、以及在 x86 上不能禁用的基于段的保护,因此你需要去理解这些基础知识。
虚拟地址、线性地址和物理地址
在 x86 的专用术语中,一个 虚拟地址 是由一个段选择器和在段中的偏移量组成。一个 线性地址 是在页面转换之前、段转换之后得到的一个地址。一个 物理地址 是段和页面转换之后得到的最终地址,它最终将进入你的物理内存中的硬件总线。
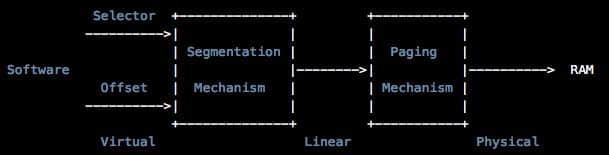
一个 C 指针是虚拟地址的“偏移量”部分。在 boot/boot.S 中我们安装了一个 全局描述符表 (GDT),它通过设置所有的段基址为 0,并且限制为 0xffffffff 来有效地禁用段转换。因此“段选择器”并不会生效,而线性地址总是等于虚拟地址的偏移量。在实验 3 中,为了设置权限级别,我们将与段有更多的交互。但是对于内存转换,我们将在整个 JOS 实验中忽略段,只专注于页转换。
回顾实验 1 中的第 3 部分,我们安装了一个简单的页表,这样内核就可以在 0xf0100000 链接的地址上运行,尽管它实际上是加载在 0x00100000 处的 ROM BIOS 的物理内存上。这个页表仅映射了 4MB 的内存。在实验中,你将要为 JOS 去设置虚拟内存布局,我们将从虚拟地址 0xf0000000 处开始扩展它,以映射物理内存的前 256MB,并映射许多其它区域的虚拟内存。
练习 3
虽然 GDB 能够通过虚拟地址访问 QEMU 的内存,它经常用于在配置虚拟内存期间检查物理内存。在实验工具指南中复习 QEMU 的监视器命令,尤其是
xp命令,它可以让你去检查物理内存。要访问 QEMU 监视器,可以在终端中按Ctrl-a c(相同的绑定返回到串行控制台)。使用 QEMU 监视器的
xp命令和 GDB 的x命令去检查相应的物理内存和虚拟内存,以确保你看到的是相同的数据。我们的打过补丁的 QEMU 版本提供一个非常有用的
info pg命令:它可以展示当前页表的一个具体描述,包括所有已映射的内存范围、权限、以及标志。原本的 QEMU 也提供一个info mem命令用于去展示一个概要信息,这个信息包含了已映射的虚拟内存范围和使用了什么权限。
在 CPU 上运行的代码,一旦处于保护模式(这是在 boot/boot.S 中所做的第一件事情)中,是没有办法去直接使用一个线性地址或物理地址的。所有的内存引用都被解释为虚拟地址,然后由 MMU 来转换,这意味着在 C 语言中的指针都是虚拟地址。
例如在物理内存分配器中,JOS 内存经常需要在不反向引用的情况下,去维护作为地址的一个很难懂的值或一个整数。有时它们是虚拟地址,而有时是物理地址。为便于在代码中证明,JOS 源文件中将它们区分为两种:类型 uintptr_t 表示一个难懂的虚拟地址,而类型 physaddr_trepresents 表示物理地址。这些类型其实不过是 32 位整数(uint32_t)的同义词,因此编译器不会阻止你将一个类型的数据指派为另一个类型!因为它们都是整数(而不是指针)类型,如果你想去反向引用它们,编译器将报错。
JOS 内核能够通过将它转换为指针类型的方式来反向引用一个 uintptr_t 类型。相反,内核不能反向引用一个物理地址,因为这是由 MMU 来转换所有的内存引用。如果你转换一个 physaddr_t 为一个指针类型,并反向引用它,你或许能够加载和存储最终结果地址(硬件将它解释为一个虚拟地址),但你并不会取得你想要的内存位置。
总结如下:
| C 类型 | 地址类型 |
|---|---|
T* |
虚拟 |
uintptr_t |
虚拟 |
physaddr_t |
物理 |
问题:
- 假设下面的 JOS 内核代码是正确的,那么变量
x应该是什么类型?uintptr_t还是physaddr_t?

JOS 内核有时需要去读取或修改它只知道其物理地址的内存。例如,添加一个映射到页表,可以要求分配物理内存去存储一个页目录,然后去初始化它们。然而,内核也和其它的软件一样,并不能跳过虚拟地址转换,内核并不能直接加载和存储物理地址。一个原因是 JOS 将重映射从虚拟地址 0xf0000000 处的物理地址 0 开始的所有的物理地址,以帮助内核去读取和写入它知道物理地址的内存。为转换一个物理地址为一个内核能够真正进行读写操作的虚拟地址,内核必须添加 0xf0000000 到物理地址以找到在重映射区域中相应的虚拟地址。你应该使用 KADDR(pa) 去做那个添加操作。
JOS 内核有时也需要能够通过给定的内核数据结构中存储的虚拟地址找到内存中的物理地址。内核全局变量和通过 boot_alloc() 分配的内存是在内核所加载的区域中,从 0xf0000000 处开始的这个所有物理内存映射的区域。因此,要转换这些区域中一个虚拟地址为物理地址时,内核能够只是简单地减去 0xf0000000 即可得到物理地址。你应该使用 PADDR(va) 去做那个减法操作。
引用计数
在以后的实验中,你将会经常遇到多个虚拟地址(或多个环境下的地址空间中)同时映射到相同的物理页面上。你将在 struct PageInfo 数据结构中的 pp_ref 字段来记录一个每个物理页面的引用计数器。如果一个物理页面的这个计数器为 0,表示这个页面已经被释放,因为它不再被使用了。一般情况下,这个计数器应该等于所有页表中物理页面出现在 UTOP 之下的次数(UTOP 之上的映射大都是在引导时由内核设置的,并且它从不会被释放,因此不需要引用计数器)。我们也使用它去跟踪放到页目录页的指针数量,反过来就是,页目录到页表页的引用数量。
使用 page_alloc 时要注意。它返回的页面引用计数总是为 0,因此,一旦对返回页做了一些操作(比如将它插入到页表),pp_ref 就应该增加。有时这需要通过其它函数(比如,page_instert)来处理,而有时这个函数是直接调用 page_alloc 来做的。
页表管理
现在,你将写一套管理页表的代码:去插入和删除线性地址到物理地址的映射表,并且在需要的时候去创建页表。
练习 4
在文件
kern/pmap.c中,你必须去实现下列函数的代码。
- pgdir_walk()
- bootmapregion()
- page_lookup()
- page_remove()
- page_insert()
check_page(),调用自mem_init(),测试你的页表管理函数。在进行下一步流程之前你应该确保它成功运行。
第 3 部分:内核地址空间
JOS 分割处理器的 32 位线性地址空间为两部分:用户环境(进程),(我们将在实验 3 中开始加载和运行),它将控制其上的布局和低位部分的内容;而内核总是维护对高位部分的完全控制。分割线的定义是在 inc/memlayout.h 中通过符号 ULIM 来划分的,它为内核保留了大约 256MB 的虚拟地址空间。这就解释了为什么我们要在实验 1 中给内核这样的一个高位链接地址的原因:如是不这样做的话,内核的虚拟地址空间将没有足够的空间去同时映射到下面的用户空间中。
你可以在 inc/memlayout.h 中找到一个图表,它有助于你去理解 JOS 内存布局,这在本实验和后面的实验中都会用到。
权限和故障隔离
由于内核和用户的内存都存在于它们各自环境的地址空间中,因此我们需要在 x86 的页表中使用权限位去允许用户代码只能访问用户所属地址空间的部分。否则,用户代码中的 bug 可能会覆写内核数据,导致系统崩溃或者发生各种莫名其妙的的故障;用户代码也可能会偷窥其它环境的私有数据。
对于 ULIM 以上部分的内存,用户环境没有任何权限,只有内核才可以读取和写入这部分内存。对于 [UTOP,ULIM] 地址范围,内核和用户都有相同的权限:它们可以读取但不能写入这个地址范围。这个地址范围是用于向用户环境暴露某些只读的内核数据结构。最后,低于 UTOP 的地址空间是为用户环境所使用的;用户环境将为访问这些内核设置权限。
初始化内核地址空间
现在,你将去配置 UTOP 以上的地址空间:内核部分的地址空间。inc/memlayout.h 中展示了你将要使用的布局。我将使用函数去写相关的线性地址到物理地址的映射配置。
练习 5
完成调用
check_page()之后在mem_init()中缺失的代码。
现在,你的代码应该通过了 check_kern_pgdir() 和 check_page_installed_pgdir() 的检查。
问题:
1、在这个时刻,页目录中的条目(行)是什么?它们映射的址址是什么?以及它们映射到哪里了?换句话说就是,尽可能多地填写这个表:
条目 虚拟地址基址 指向(逻辑上): 1023 ? 物理内存顶部 4MB 的页表 1022 ? ? . ? ? . ? ? . ? ? 2 0x00800000 ? 1 0x00400000 ? 0 0x00000000 [参见下一问题] 2、(来自课程 3) 我们将内核和用户环境放在相同的地址空间中。为什么用户程序不能去读取和写入内核的内存?有什么特殊机制保护内核内存?
3、这个操作系统能够支持的最大的物理内存数量是多少?为什么?
4、如果我们真的拥有最大数量的物理内存,有多少空间的开销用于管理内存?这个开销可以减少吗?
5、复习在
kern/entry.S和kern/entrypgdir.c中的页表设置。一旦我们打开分页,EIP 仍是一个很小的数字(稍大于 1MB)。在什么情况下,我们转而去运行在 KERNBASE 之上的一个 EIP?当我们启用分页并开始在 KERNBASE 之上运行一个 EIP 时,是什么让我们能够一个很低的 EIP 上持续运行?为什么这种转变是必需的?
地址空间布局的其它选择
在 JOS 中我们使用的地址空间布局并不是我们唯一的选择。一个操作系统可以在低位的线性地址上映射内核,而为用户进程保留线性地址的高位部分。然而,x86 内核一般并不采用这种方法,因为 x86 向后兼容模式之一(被称为“虚拟 8086 模式”)“不可改变地”在处理器使用线性地址空间的最下面部分,所以,如果内核被映射到这里是根本无法使用的。
虽然很困难,但是设计这样的内核是有这种可能的,即:不为处理器自身保留任何固定的线性地址或虚拟地址空间,而有效地允许用户级进程不受限制地使用整个 4GB 的虚拟地址空间 —— 同时还要在这些进程之间充分保护内核以及不同的进程之间相互受保护!
将内核的内存分配系统进行概括类推,以支持二次幂为单位的各种页大小,从 4KB 到一些你选择的合理的最大值。你务必要有一些方法,将较大的分配单位按需分割为一些较小的单位,以及在需要时,将多个较小的分配单位合并为一个较大的分配单位。想一想在这样的一个系统中可能会出现些什么样的问题。
这个实验做完了。确保你通过了所有的等级测试,并记得在 answers-lab2.txt 中写下你对上述问题的答案。提交你的改变(包括添加 answers-lab2.txt 文件),并在 lab 目录下输入 make handin 去提交你的实验。




江湖再见