

Facebook 经常使用数据驱动的分析方法来做决策。在过去的几年,用户和产品的增长已经需要我们的分析工程师一次查询就要操作数十 TB 大小的数据集。我们的一些批量分析执行在古老的 Hive 平台( Apache Hive 由 Facebook 贡献于 2009 年)和 Corona 上——这是我们定制的 MapReduce 实现。Facebook 还不断增加其对 Presto 的用量,用于对几个包括 Hive 在内的内部数据存储的 ANSI-SQL 查询。我们也支持其他分析类型,比如 图数据库处理 和机器学习(Apache Giraph)和流(例如:Puma、Swift 和 Stylus)。
同时 Facebook 的各种产品涵盖了广泛的分析领域,我们与开源社区不断保持沟通,以便共享我们的经验并从其他人那里学习。Apache Spark 于 2009 年在加州大学伯克利分校的 AMPLab 由 Matei Zaharia 发起,后来在2013 年贡献给 Apache。它是目前增长最快的数据处理平台之一,由于它能支持流、批量、命令式(RDD)、声明式(SQL)、图数据库和机器学习等用例,而且所有这些都内置在相同的 API 和底层计算引擎中。Spark 可以有效地利用更大量级的内存,优化整个 流水线 中的代码,并跨任务重用 JVM 以获得更好的性能。最近我们感觉 Spark 已经成熟,我们可以在一些批量处理用例方面把它与 Hive 相比较。在这篇文章其余的部分,我们讲述了在扩展 Spark 来替代我们一个 Hive 工作任务时的所得到经验和学习到的教训。
用例:实体排名的特征准备
Facebook 会以多种方式做实时的 实体 排名。对于一些在线服务平台,原始特征值是由 Hive 线下生成的,然后将数据加载到实时关联查询系统。我们在几年前建立的基于 Hive 的老式基础设施属于计算资源密集型,且很难维护,因为其流水线被划分成数百个较小的 Hive 任务。为了可以使用更加新的特征数据和提升可管理性,我们拿一个现有的流水线试着将其迁移至 Spark。
以前的 Hive 实现
基于 Hive 的流水线由三个逻辑 阶段 组成,每个阶段对应由 entity_id 划分的数百个较小的 Hive 作业,因为在每个阶段运行大型 Hive 作业 不太可靠,并受到每个作业的最大 任务 数量的限制。
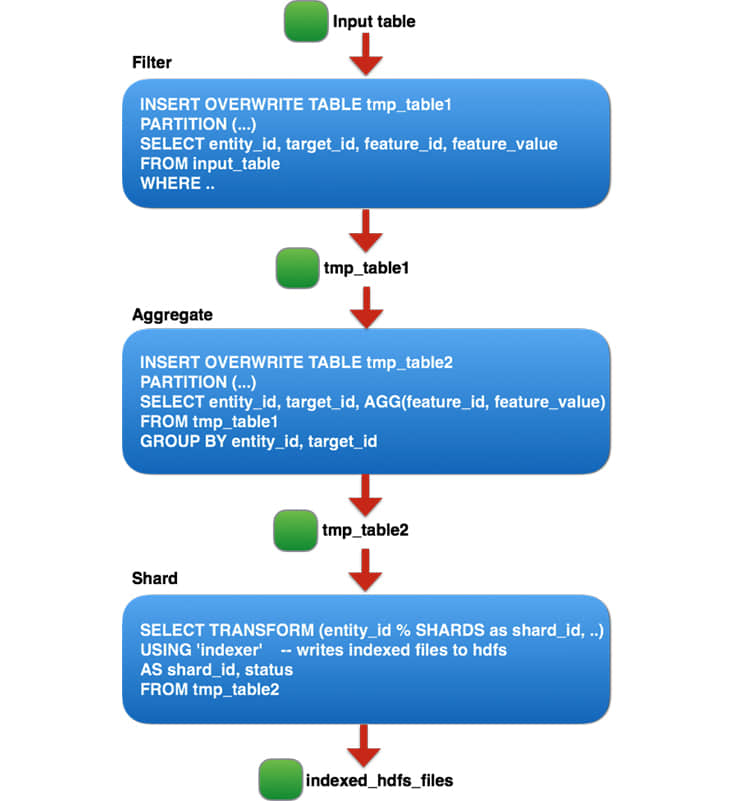
这三个逻辑阶段可以总结如下:
- 过滤出非产品的特征和噪点。
- 在每个(entity_id, target_id)对上进行聚合。
- 将表格分割成 N 个分片,并通过自定义二进制文件管理每个分片,以生成用于在线查询的自定义索引文件。
基于 Hive 的流水线建立该索引大概要三天完成。它也难于管理,因为该流水线包含上百个分片的作业,使监控也变得困难。同时也没有好的方法来估算流水线进度或计算剩余时间。考虑到 Hive 流水线的上述限制,我们决定建立一个更快、更易于管理的 Spark 流水线。
Spark 实现
全量的调试会很慢,有挑战,而且是资源密集型的。我们从转换基于 Hive 流水线的最资源密集型的第二阶段开始。我们以一个 50GB 的压缩输入例子开始,然后逐渐扩展到 300GB、1TB,然后到 20TB。在每次规模增长时,我们都解决了性能和稳定性问题,但是实验到 20TB 时,我们发现了最大的改善机会。
运行 20TB 的输入时,我们发现,由于大量的任务导致我们生成了太多输出文件(每个大小在 100MB 左右)。在 10 小时的作业运行时中,有三分之一是用在将文件从阶段目录移动到 HDFS 中的最终目录。起初,我们考虑两个方案:要么改善 HDFS 中的批量重命名来支持我们的用例,或者配置 Spark 生成更少的输出文件(这很难,由于在这一步有大量的任务 — 70000 个)。我们退一步来看这个问题,考虑第三种方案。由于我们在流水线的第二步中生成的 tmp_table2 表是临时的,仅用于存储流水线的中间输出,所以对于 TB 级数据的单一读取作业任务,我们基本上是在压缩、序列化和复制三个副本。相反,我们更进一步:移除两个临时表并整合 Hive 过程的所有三个部分到一个单独的 Spark 作业,读取 60TB 的压缩数据然后对 90TB 的数据执行 重排 和 排序 。最终的 Spark 作业如下:
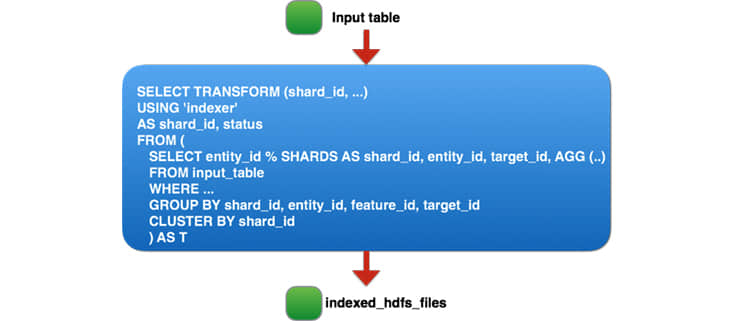
对于我们的作业如何规划 Spark?
当然,为如此大的流水线运行一个单独的 Spark 任务,第一次尝试没有成功,甚至是第十次尝试也没有。据我们所知,从 重排 的数据大小来说,这是现实世界最大的 Spark 作业(Databrick 的 PB 级排序是以合成数据来说)。我们对核心 Spark 基础架构和我们的应用程序进行了许多改进和优化使这个作业得以运行。这种努力的优势在于,许多这些改进适用于 Spark 的其他大型作业任务,我们将所有的工作回馈给开源 Apache Spark 项目 - 有关详细信息请参阅 JIRA。下面,我们将重点讲述将实体排名流水线之一部署到生产环境所做的重大改进。
可靠性修复
处理频繁的节点重启
为了可靠地执行长时间运行作业,我们希望系统能够容错并可以从故障中恢复(主要是由于平时的维护或软件错误导致的机器重启所引发的)。虽然 Spark 设计为可以容忍机器重启,但我们发现它在足够强健到可以处理常见故障之前还有各种错误/问题需要解决。
- 使 PipedRDD 稳健的 获取 失败(SPARK-13793):PipedRDD 以前的实现不够强大,无法处理由于节点重启而导致的获取失败,并且只要出现获取失败,该作业就会失败。我们在 PipedRDD 中进行了更改,优雅的处理获取失败,使该作业可以从这种类型的获取失败中恢复。
- 可配置的最大获取失败次数(SPARK-13369):对于这种长时间运行的作业,由于机器重启而引起的获取失败概率显着增加。在 Spark 中每个阶段的最大允许的获取失败次数是硬编码的,因此,当达到最大数量时该作业将失败。我们做了一个改变,使它是可配置的,并且在这个用例中将其从 4 增长到 20,从而使作业更稳健。
- 减少集群重启混乱:长时间运行作业应该可以在集群重启后存留,所以我们不用等着处理完成。Spark 的可重启的 重排 服务功能可以使我们在节点重启后保留 重排 文件。最重要的是,我们在 Spark 驱动程序中实现了一项功能,可以暂停执行任务调度,所以不会由于集群重启而导致的过多的任务失败,从而导致作业失败。
其他的可靠性修复
- 响应迟钝的驱动程序(SPARK-13279):在添加任务时,由于 O(N ^ 2) 复杂度的操作,Spark 驱动程序被卡住,导致该作业最终被卡住和死亡。 我们通过删除不必要的 O(N ^ 2) 操作来修复问题。
- 过多的驱动 推测 :我们发现,Spark 驱动程序在管理大量任务时花费了大量的时间推测。 在短期内,我们禁止这个作业的推测。在长期,我们正在努力改变 Spark 驱动程序,以减少推测时间。
- 由于大型缓冲区的整数溢出导致的 TimSort 问题(SPARK-13850):我们发现 Spark 的不安全内存操作有一个漏洞,导致 TimSort 中的内存损坏。 感谢 Databricks 的人解决了这个问题,这使我们能够在大内存缓冲区中运行。
- 调整重排(shuffle)服务来处理大量连接:在重排阶段,我们看到许多执行程序在尝试连接重排服务时超时。 增加 Netty 服务器的线程(spark.shuffle.io.serverThreads)和积压(spark.shuffle.io.backLog)的数量解决了这个问题。
- 修复 Spark 执行程序 OOM(SPARK-13958)(deal maker):首先在每个主机上打包超过四个 聚合 任务是很困难的。Spark 执行程序会内存溢出,因为排序程序(sorter)中存在导致无限增长的指针数组的漏洞。当不再有可用的内存用于指针数组增长时,我们通过强制将数据溢出到磁盘来修复问题。因此,现在我们可以每主机运行 24 个任务,而不会内存溢出。
性能改进
在实施上述可靠性改进后,我们能够可靠地运行 Spark 作业了。基于这一点,我们将精力转向与性能相关的项目,以充分发挥 Spark 的作用。我们使用 Spark 的指标和几个分析器来查找一些性能瓶颈。
我们用来查找性能瓶颈的工具
- Spark UI 指标:Spark UI 可以很好地了解在特定阶段所花费的时间。每个任务的执行时间被分为子阶段,以便更容易地找到作业中的瓶颈。
- Jstack:Spark UI 还在执行程序进程上提供了一个按需分配的 jstack 函数,可用于中查找热点代码。
- Spark 的 Linux Perf / 火焰图 支持:尽管上述两个工具非常方便,但它们并不提供同时在数百台机器上运行的作业的 CPU 分析的聚合视图。在每个作业的基础上,我们添加了支持 Perf 分析(通过 libperfagent 的 Java 符号),并可以自定义采样的持续时间/频率。使用我们的内部指标收集框架,将分析样本聚合并显示为整个执行程序的火焰图。
性能优化
- 修复 排序程序 中的内存泄漏(SPARK-14363)(30% 速度提升):我们发现了一个问题,当任务释放所有内存页时指针数组却未被释放。 因此,大量的内存未被使用,并导致频繁的溢出和执行程序 OOM。 我们现在进行了改变,正确地释放内存,并使大的分类运行更有效。 我们注意到,这一变化后 CPU 改善了 30%。
- Snappy 优化(SPARK-14277)(10% 速度提升):有个 JNI 方法(Snappy.ArrayCopy)在每一行被读取/写入时都会被调用。 我们发现了这个问题,Snappy 的行为被改为使用非 JNI 的 System.ArrayCopy 代替。 这一改变节约了大约 10% 的 CPU。
- 减少重排的写入延迟(SPARK-5581)(高达 50% 的速度提升):在 映射 方面,当将重排数据写入磁盘时,映射任务为每个分区打开并关闭相同的文件。 我们做了一个修复,以避免不必要的打开/关闭,对于大量写入重排分区的作业来说,我们观察到高达 50% 的 CPU 提升。
- 解决由于获取失败导致的重复任务运行问题(SPARK-14649):当获取失败发生时,Spark 驱动程序会重新提交已运行的任务,导致性能下降。 我们通过避免重新运行运行的任务来解决这个问题,我们看到当获取失败发生时该作业会更加稳定。
- 可配置 PipedRDD 的缓冲区大小(SPARK-14542)(10% 速度提升):在使用 PipedRDD 时,我们发现将数据从分类程序传输到管道进程的默认缓冲区的大小太小,我们的作业要花费超过 10% 的时间复制数据。我们使缓冲区大小可配置,以避免这个瓶颈。
- 缓存索引文件以加速重排获取(SPARK-15074):我们观察到重排服务经常成为瓶颈, 减少程序 花费 10% 至 15% 的时间等待获取 映射 数据。通过深入了解问题,我们发现,重排服务为每个重排获取打开/关闭重排索引文件。我们进行了更改以缓存索引信息,以便我们可以避免文件打开/关闭,并重新使用该索引信息以便后续获取。这个变化将总的重排时间减少了 50%。
- 降低重排字节写入指标的更新频率(SPARK-15569)(高达 20% 的速度提升):使用 Spark 的 Linux Perf 集成,我们发现大约 20% 的 CPU 时间正在花费探测和更新写入的重排字节写入指标上。
- 可配置排序程序(sorter)的初始缓冲区大小(SPARK-15958)(高达 5% 的速度提升): 排序程序 的默认初始缓冲区大小太小(4 KB),我们发现它对于大型工作负载而言非常小 - 所以我们在缓冲区耗尽和内容复制上浪费了大量的时间。我们做了一个更改,使缓冲区大小可配置,并且缓冲区大小为 64 MB,我们可以避免大量的数据复制,使作业的速度提高约 5%。
- 配置任务数量:由于我们的输入大小为 60T,每个 HDFS 块大小为 256M,因此我们为该作业产生了超过 250,000 个任务。尽管我们能够以如此多的任务来运行 Spark 作业,但是我们发现,当任务数量过高时,性能会下降。我们引入了一个配置参数,使 映射 输入大小可配置,因此我们可以通过将输入分割大小设置为 2 GB 来将该数量减少 8 倍。
在所有这些可靠性和性能改进之后,我们很高兴地报告,我们为我们的实体排名系统之一构建和部署了一个更快、更易于管理的流水线,并且我们提供了在 Spark 中运行其他类似作业的能力。
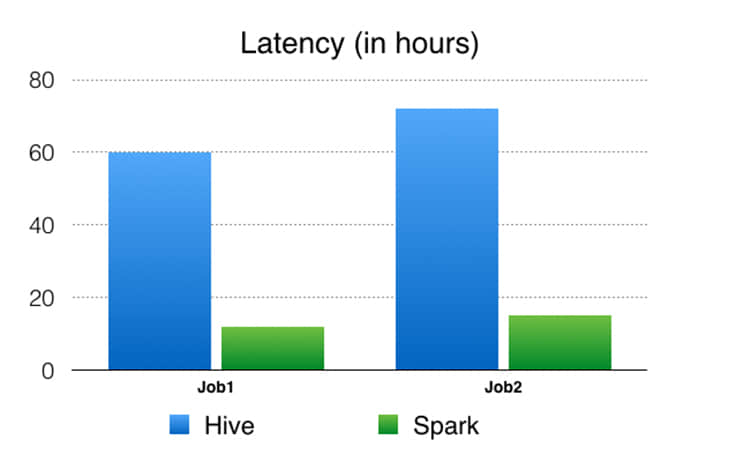
Spark 流水线与 Hive 流水线性能对比
我们使用以下性能指标来比较 Spark 流水线与 Hive 流水线。请注意,这些数字并不是在查询或作业级别的直接比较 Spark 与 Hive ,而是比较使用灵活的计算引擎(例如 Spark)构建优化的流水线,而不是比较仅在查询/作业级别(如 Hive)操作的计算引擎。
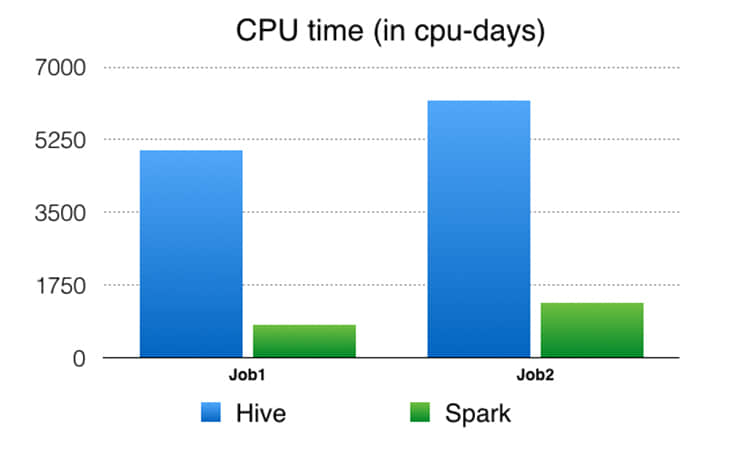
CPU 时间:这是从系统角度看 CPU 使用。例如,你在一个 32 核机器上使用 50% 的 CPU 10 秒运行一个单进程任务,然后你的 CPU 时间应该是 32 * 0.5 * 10 = 160 CPU 秒。
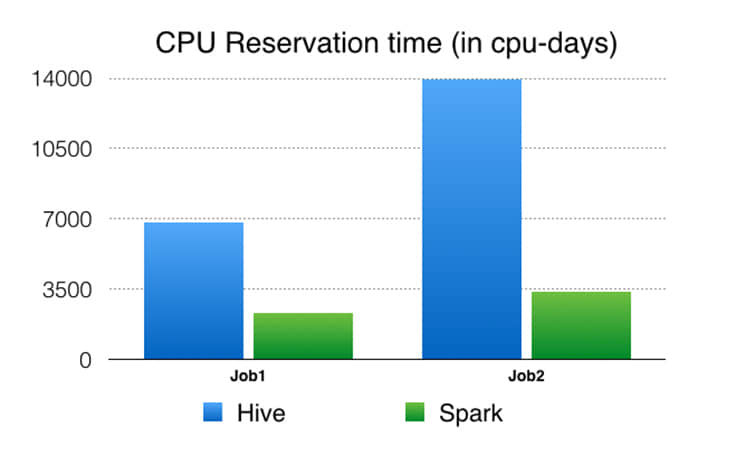
CPU 预留时间:这是从资源管理框架的角度来看 CPU 预留。例如,如果我们保留 32 位机器 10 秒钟来运行作业,则CPU 预留时间为 32 * 10 = 320 CPU 秒。CPU 时间与 CPU 预留时间的比率反映了我们如何在集群上利用预留的CPU 资源。当准确时,与 CPU 时间相比,预留时间在运行相同工作负载时可以更好地比较执行引擎。例如,如果一个进程需要 1 个 CPU 的时间才能运行,但是必须保留 100 个 CPU 秒,则该指标的效率要低于需要 10 个 CPU 秒而仅保留 10 个 CPU 秒来执行相同的工作量的进程。我们还计算内存预留时间,但不包括在这里,因为其数字类似于 CPU 预留时间,因为在同一硬件上运行实验,而在 Spark 和 Hive 的情况下,我们不会将数据缓存在内存中。Spark 有能力在内存中缓存数据,但是由于我们的集群内存限制,我们决定类似与 Hive 一样工作在核心外部。
等待时间:端到端的工作流失时间。
结论和未来工作
Facebook 的性能和可扩展的分析在产品开发中给予了协助。Apache Spark 提供了将各种分析用例统一为单一 API 和高效计算引擎的独特功能。我们挑战了 Spark,来将一个分解成数百个 Hive 作业的流水线替换成一个 Spark 作业。通过一系列的性能和可靠性改进之后,我们可以将 Spark 扩大到处理我们在生产中的实体排名数据处理用例之一。 在这个特殊用例中,我们展示了 Spark 可以可靠地重排和排序 90 TB+ 的中间数据,并在一个单一作业中运行了 25 万个任务。 与旧的基于 Hive 的流水线相比,基于 Spark 的流水线产生了显着的性能改进(4.5-6 倍 CPU,3-4 倍资源预留和大约 5 倍的延迟),并且已经投入使用了几个月。
虽然本文详细介绍了我们 Spark 最具挑战性的用例,越来越多的客户团队已将 Spark 工作负载部署到生产中。 性能 、可维护性和灵活性是继续推动更多用例到 Spark 的优势。 Facebook 很高兴成为 Spark 开源社区的一部分,并将共同开发 Spark 充分发挥其潜力。
via: https://code.facebook.com/posts/1671373793181703/apache-spark-scale-a-60-tb-production-use-case/
作者:Sital Kedia, 王硕杰, Avery Ching 译者:wyangsun 校对:wxy





FACEBOOK用的是哪个JAVA呢??!!