
如果你喜欢做‘排名前10’之类的列表但又有点不好意思这样说,那么告诉人们你热爱数据的探索。为了进一步打动他们,向他们解释你在命令行间的数据探索。但是不要告诉他们这其实很容易,以免你的好形象就这样被毁灭了哦!

在这篇文章中,我将基于GNU/Linux工具和'单列表格'(也就是我所说的简单列表)来做一些数据探索。如若想在这里通过命令行查看更多的信息,请查看'man'页,或者在“注释”部分求解。
密码
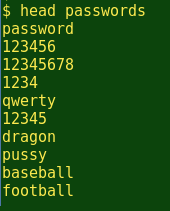
在第一个列表里探讨的是马克.伯内特2011著的关于10000 个最常用的密码汇编。这个列表是有序的、使用最频繁的,也是广为人知的阶乘“密码”的最常用来源之一,与“123456”并列排名第二。在这里,我把该列表放到一个名为“passwords”的文件中,并且使用head命令把排名前10的列出来了:
(伯内特解释他是如何收集这些密码的这里。你会注意到在列表中他把所有大写字母都转换成小写的。)
OK,所以'password'是伯内特列表的顶部。那么每个数字呢?
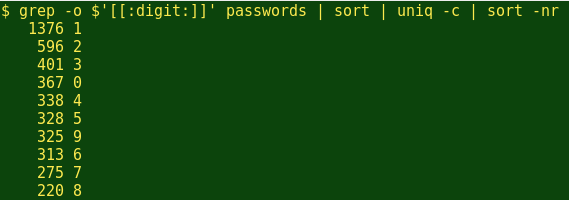
非常有趣的是!数字'1'出现在密码列表中的次数多于第二个最常用数字'2'的两倍,而且,除了0和9之外,这十个数字出现的次数以其数字顺序排列。而排名前10的字母呢?
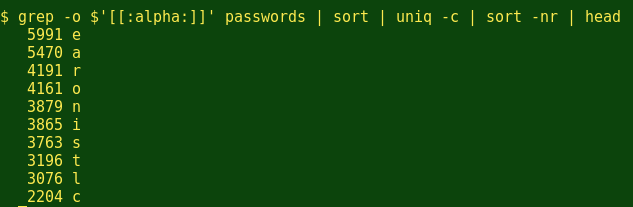
在 passwords 文件中出现最频繁的字母依次是EARONISTLC,类似于EAIRTONSLC,这是至少一个出版的表格中提到的常用英文单词中出现的字频。这是否意味着,大部分密码其实是一些常见的英语单词呢,也许会参杂一些数字呢?
为了找到答案,我先把密码转换成一个纯字母的字符串列表,然后看看有多少字符串是可以在英语词典中找到的。
首先我将通过 sed 命令删除所有密码中的数字,然后删除所有的标点符号,再删除所有的空行。这将创建出一个纯字母的密码列表。然后我通过sort 和 uniq来修剪列表的排序,将重复项取出。(例如,'abc1234def'和'abc1!2!3!def!'都剔除剩下'abcdef'.) 。根据wc命令,我把1000个密码减至成8583个纯字母的字符串:

我经常使用一本便携式的英语字典,我通常会使用usr/share/dict/american-english,这个文件是来自Debian Linux的一个发行版本。它包含了99171个单词。我会先通过tr命令将这个词表转换为纯小写的,然后使用sort 和 uniq删除掉任何重复的条目排序(例如'A' 和 'a' 都将成为 'a')。这样就将词表的数量减至97723项了:

我现在可以用comm命令及'-23'的参数来比较两个列表,并报告纯字母文件中而没有出现在字典中的单词:

总数是3137,所以至少有8583 -3137 = 5446个'核心'密码在伯纳特的纯小写字母列表中(大约63%)是简单的英语单词,或者是简单的单词附加一些数字或者标点符号。我之所以说“至少”,是因为在3137个字符串中有很大比例是只有经过轻微修改的纯英语单词、名称、或者在/usr/share字典中未能找到的名称修改而成的。在LA项中,例如,'labtec', 'ladyboy', 'lakeside', 'lalakers', 'lalala', 'laserjet', 'lasvegas', 'lavalamp' 和 'lawman'.
地名
在之前的一篇Linux Rain article,我描述了如何建立一张37万项澳大利亚的地名表。有了它,我现在可以回答一些类似这样的关键问题“Round Hill是澳大利亚山脉中最流行的名字吗?”和“桑迪是沙滩之最,而岩溪峡谷呢?”
在地名表中地名字段的排名第2,所以这里有:
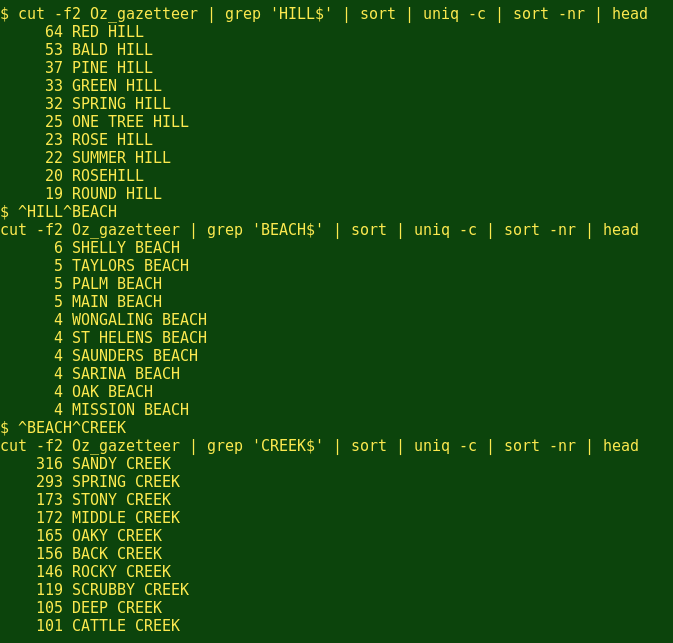
哇。我当时甚至没有关闭这个终端。(但是请注意到我是如何通过^string1^string2命令保存打印的内容。它重复着最后一个命令,但是用第2个字符串代替了第1个字符串。这是多么有用的BASH绝招!)
另一个亟待解决的问题是有多少地名有'Mile'在其中,例如'Six Mile Creek',而他们的排名又是如何: 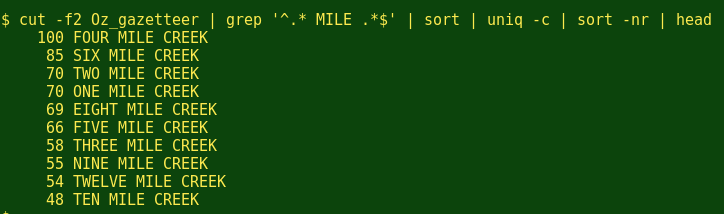
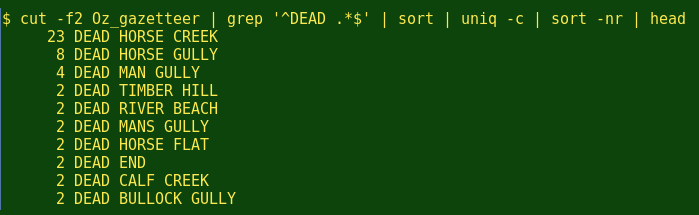
我在我的澳洲之旅发现有很多Dead Horse Creeks,因此有这些地名:
种类
第三个列表是探索我今年出版的1961-2010年期间澳大利亚新种类昆虫名。从这个列表中,我去掉所有“物种的绰号”,就是种群组合的第二部分,比如像智人(你和我)和西方蜜蜂(欧洲蜜蜂)。
(科技小贴士:这个昆虫表,可以从开发数据Zenodo库中https://zenodo.org/record/10481取得,包括亚种。在我的‘top 10’练习中,我首先分离出所有独特的种群组合,这样避免了重复的,例如蜜蜂iberica的亚种,以避免蜜蜂的绰号intermissa,等等。最后一个物种文件有18155个绰号。)
大多数人讲科学名称带玩笑式地用'-us'结局,如'Biggus buggus'。那么昆虫学家呢?有几个不错的,用命令行的方式获取字符串的最后2个字母,在这里我都会用到这2个:
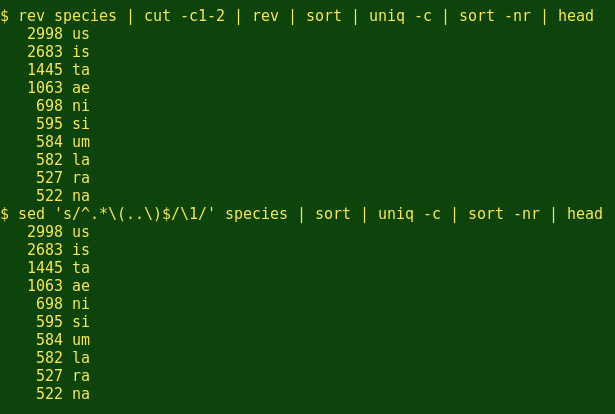
耶!昆虫学家喜欢也‘-us’结尾。接下来,我不知道有多少物种是以我的家乡Tasmania州来命名的?(下面我想看看前100行,来确保我得到的所有'tasman'组合.)
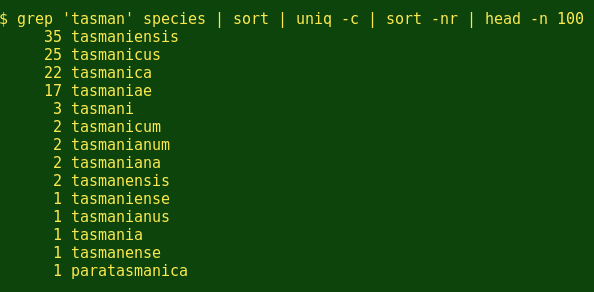
那么昆士兰呢?

一般来说,昆虫物种名单中的前10名分别是什么呢?
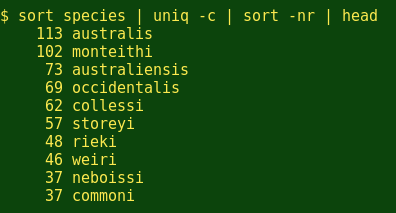
嗯,除了明显的'australis'和'australiensis',而地理方面的'occidentalis'(西部),另外昆虫学家创建7个在10个最流行列表中的绰号已经履行了其它昆虫学家的意愿。(绰号'commoni'是给澳大利亚蝴蝶和蛾专家Ian F.B. Common[1917-2006]的荣誉。)
演变
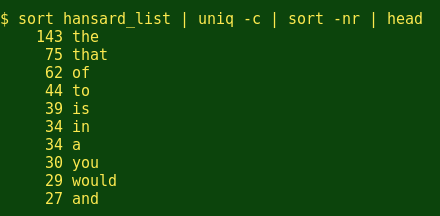
上面的这些命令用在简单列表上。要从简单的列表变成文本块,那就再次需要我们的命令行朋友了。例如,我把澳大利亚参议院于2014年7月16日的演讲保存成文本文件hansard。将hansard分割成一个单词列表: 
现在看看讲话中的单词使用频率:
即将推出...
从多列的表中做'top 10'等排名,需要更多些的命令行工具。我将会在未来的文章中证明他们的用处。
via: http://thelinuxrain.com/articles/top-10-fun-on-the-command-line
原文作者:Bob Mesibov(Bob Mesibov 是塔斯马尼亚人,已经退休,热衷于 Linux tinkerer)




江湖再见